
 0000-0002-5865-6403
0000-0002-5865-6403ECHR Open Data - Build and Deployment Process for an open source data project
About this entry
![]() This entry is part of a serie on the engineering part behind the European Court of Human Rights Open Project (ECHR-OD).
This entry is part of a serie on the engineering part behind the European Court of Human Rights Open Project (ECHR-OD).
Introduction¶
The European Court of Human Rights Open Project (ECHR-OD) aims at providing data about the European Court of Human Rights. To reach this objective, the project follows few standards to ensure the highest possible data quality. In particular,
- no data is manipulated by hand,
- the whole creation process is available and open-source such that the consummable data can be recreated from scratch,
- each generated piece of data must be versionned and intermediate file must be publicly available.
This is particularily important because on top of the usual pitfals common to all open-source projects, data projects can also suffer from poor data quality. The large amount of data makes it barely impossible to check for every chunk of data, and a lot of malformed data might go undiscovered, even with proper QA tests.
In this article, I present the general DevOps strategy adopted for the ECHR-OD project. Bare in mind that this project is managed only by myself and on my free time, and with very limited resources. Therefore, many aspects presented here are engineered taking into account these constraints. In other words, many parts would not scale for first class industrial projects.
Following the above-mentioned principles, we defined the following constraints on the release process:
- The build and deployment must happen automatically on a regular basis,
- The build and deployment must be fully automated,
- The only point of failure must be connectivity or hardware (i.e. not the code, QA must be enforced properly, which is outside the scope of this entry),
- A build failure should not be released but also not impact future build attempt nor production.
High Level Picture¶
The projects is composed of two main components:
- The process of collecting and processing the data from scratch,
- The explorer, a web component that serves three purposes:
- the main frontend for the project, including downloading the latest data,
- the API to programmatically retrieve the data,
- the explorer itself to visualize and explore the data.
Both have a separated git repository on GitHub. Both components are containerized for scalability, convenience and reproducibility.
The container process generates a build build_name in a folder build. This folder is mounted into the container explorer which loads the latest build at startup.
The whole build and deployment strategy relies on three elements:
- GitHub Workflows, that is our starting point for automations and most QA related tasks,
- ECHR-OD Workflows, designed similarily to GitHub’s one, that enable modular build for tight resources,
- A Runner, which in this case is a small dedicated server with only 2Gb RAM, and serves both to host the explorer but also to build the data.
The explorer component runs behind a NGINX reverse-proxy.
The release (build and deployment) process is is illustrated by the following sequence diagram:
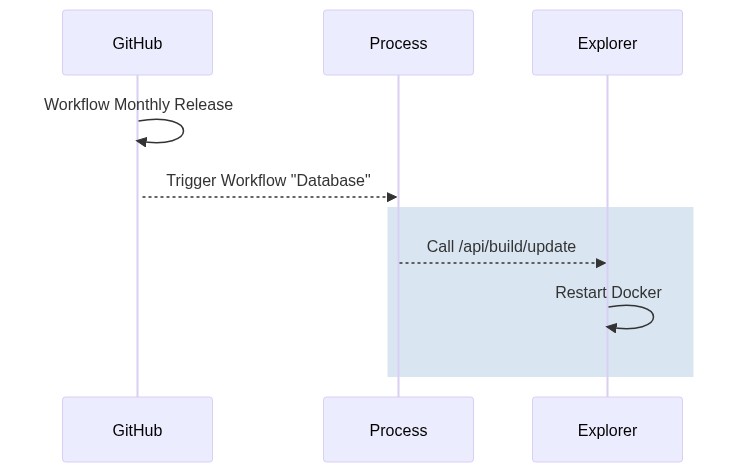
The three steps can be described as follows:
- Every month, the Cyclic Database Release workflow is automatically triggered by GitHub.
- Build the image with the latest source
- Trigger test and coverage
- Build a small database with only 100 documents
- Push the image to docker.io
- Trigger ECHR-OD Workflow “Deploy”
- The ECHR-OD Workflow “Database” is then started
- The endpoint
/api/build/updateof the explorer API is called which trigger the update and the container reboot
Limited resources
Because the server we use had only 2Gb RAM, it is impossible to regenerate the NLP models, including entity extraction, Bag-of-Words and associated models. For this reason, the monthly release includes only the database creation. The NLP models are regenerated once in a while manually.
You can support this project through my GitHub sponsor page. A larger sponsor value would eneable me to pay for a server capable of regenerating the language models on a regular basis.
Deployment and Update¶
Deploy Workflow¶
The workflow “Deploy” consists of a single action that does the following:
- Open a SSH connection to a given server,
- Clone a repository in a given location if it does not exist,
- Checkout the new code from
origin, - Create a
tmuxsession and attach, - Trigger the workflow specified in the parameters of the Deploy workflow, including the final endpoint call specified (in our case
/api/v1/build/update), - Detach the process
The source code for the action “Deploy” can be found here.
GitHub Action usage limits
At this stage, the GitHub Workflow “Cyclic Database Release” will finish. This means that there is no way for GitHub to alert us if a build fails. The reason the process is detached is because each job is limited to 6h, and 72h for a workflow, which is not enough for our purposes. However, if a build fails, we are still informed by the badge produced thanks to the API described thereafter. On top of that, a failing build does not impact production as it will not be deployed, thus an acceptable unconvenience at our level.
Build History, Build API and Build upgrade¶
For the explorer container to know that there is a new build, we introduced the build history and build info. Whenever a build is finished, a short summary is appended to the build build/.build_history and a descriptive file build_info.yml is added to build/<build_name>.
Current and Latest build
Latest build refers to the latest attempt performed buy the workflow. Current build refers to the build currently served by the explorer (i.e. in production).
The explorer provides a simple API, mostly for internal usage, to manage build status:
-
Latest build status for badge
/api/v1/build/status:
{"schemaVersion":1,"label":"Database Update","message":"2020/12/19 23:04:48","color":"green"}
-
Current build status
/api/v1/build/current:
{"build_time":"2020/12/19 23:04:48"} -
Check if a new build is available
/api/v1/build/new_build_available:
[false,null]or[true,<build_name>]
and the most important:
- Update the current build
/api/v1/build/update:- Check if there is no running build and if a new build is available
- Create a backup for the current build in case it needs to be rolled back
- Copy and replace the current build by the new build
- Restart the
explorercontainer
The last operation is slightly technical, because we need to restart the container from the container. But ultimately, the container is restarted and the new SQLite database is loaded such that the explorer can serve the updated data.
Conclusion¶
As we have seen, the main challenges faced by ECHR-OD are the lack of resources and the time constraint on GitHub Workflows. Initially, GitHub Workflows are made for pure software DevOps, and therefore, a time limit of 72h might be reasonable. However, for data science projects with a need to (pre)process large amount of data on a regular basis, this limit is easy to reach. We get around this limit by using our own server and a flexible and modular workflow system, inspired by GitHub and that we will describe in another entry.
Another engineering challenge was the properly synchronized the process container with the explorer container such that the explorer container is aware of the existence a new build and can restart itself.
Finally, we ensure that the production data is not disturbed by a failing build, which should happen only in case of problem with the runner (most likely connectivity or hardware issue).